
Exploring Session-Level Google Analytics Data - Part 1
Download HEAVY.AI Free, a full-featured version available for use at no cost.
GET FREE LICENSEHave you felt limited by the capabilities of Google Analytics standard user interface? Would you like to slice & dice your analytics big data with multiple filters to intuitively explore and gain more insights?
If yes, then this multi-part blog series, discussing how to explore Google Analytics with the MapD platform, has the answers for you. MapD is a GPU-accelerated SQL engine (MapD Core) and a visual analytics platform (MapD Immerse). The application that we will discuss in this blog downloads raw, session-level Google Analytics data in CSV format for a specified date range. The downloaded data is then formatted, compressed (gzip), and uploaded to your MapD server. You can also choose not to automatically upload the data to MapD and instead import the gzipped CSV file using the Immerse user interface. The application is written in Python using the Google API Client Libraries and is based on the original work from Ryan Praski and Google Developer’s Hello Analytics API: Python quickstart for service accounts sample program.
Setup
There are a few steps that must be done in order to use this Python application.
Prerequisite 1: Google Analytics Service Account
The Python application uses a service account to call the Google API, so that the users aren't directly involved. You can skip this step if you have already enabled Analytics API and created a service account.
Step 1: Enable the use of API for your Google account by going to Register your application for Analytics API in Google API Console
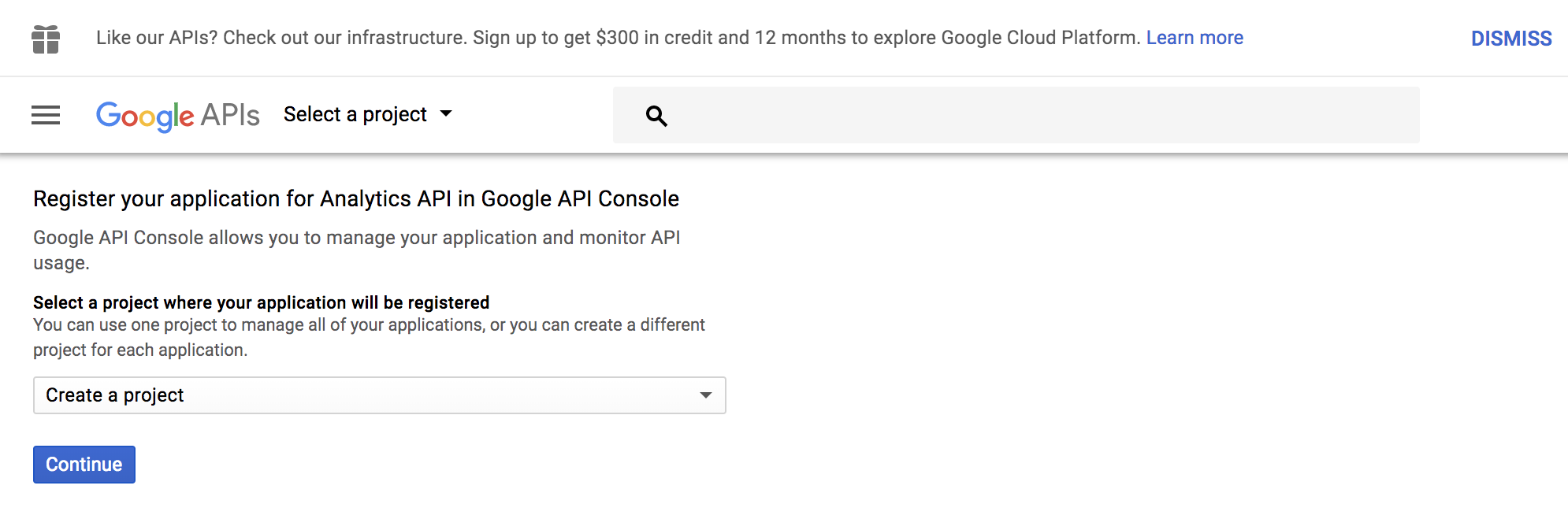
Click Continue to create a project.
Step 2: This will enable the API access, now press Go to credentials.
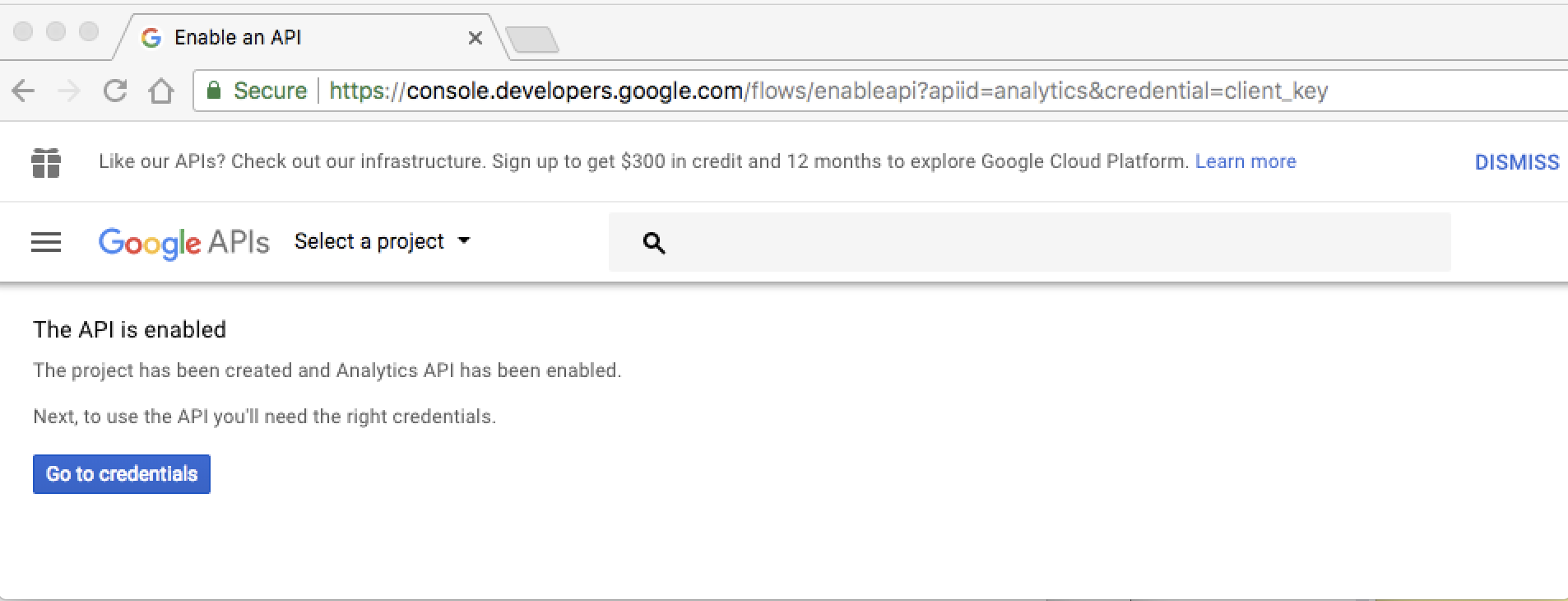
Step 3: Then fill the Add credentials to your project as shown in the caption below and press What credentials do I need?
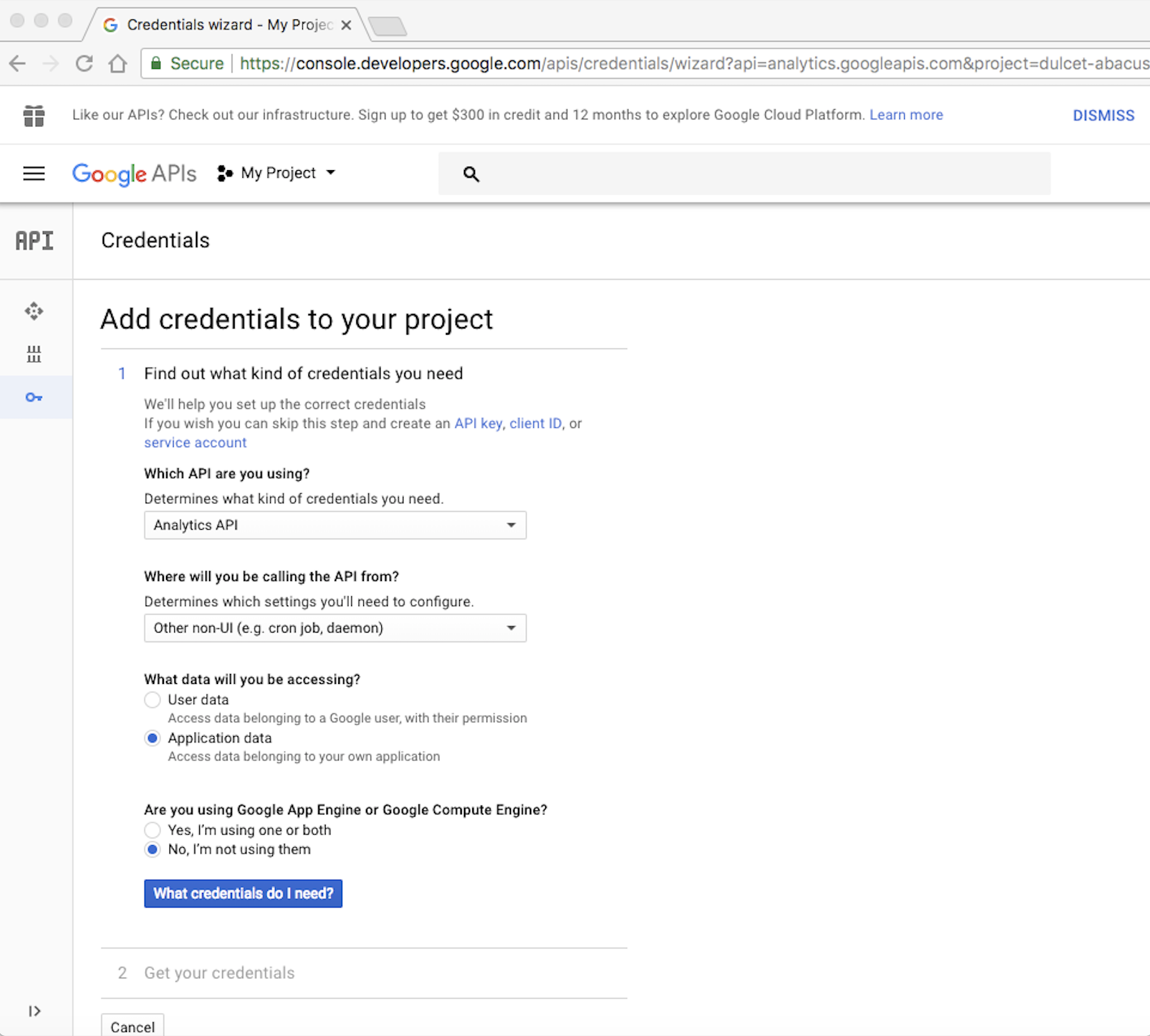
Step 4: Fill the Add credentials to your project as shown in the caption below and press Continue. Make sure to select JSON for the key type. Make sure you only use alphanumeric characters in the service account name, no spaces allowed.
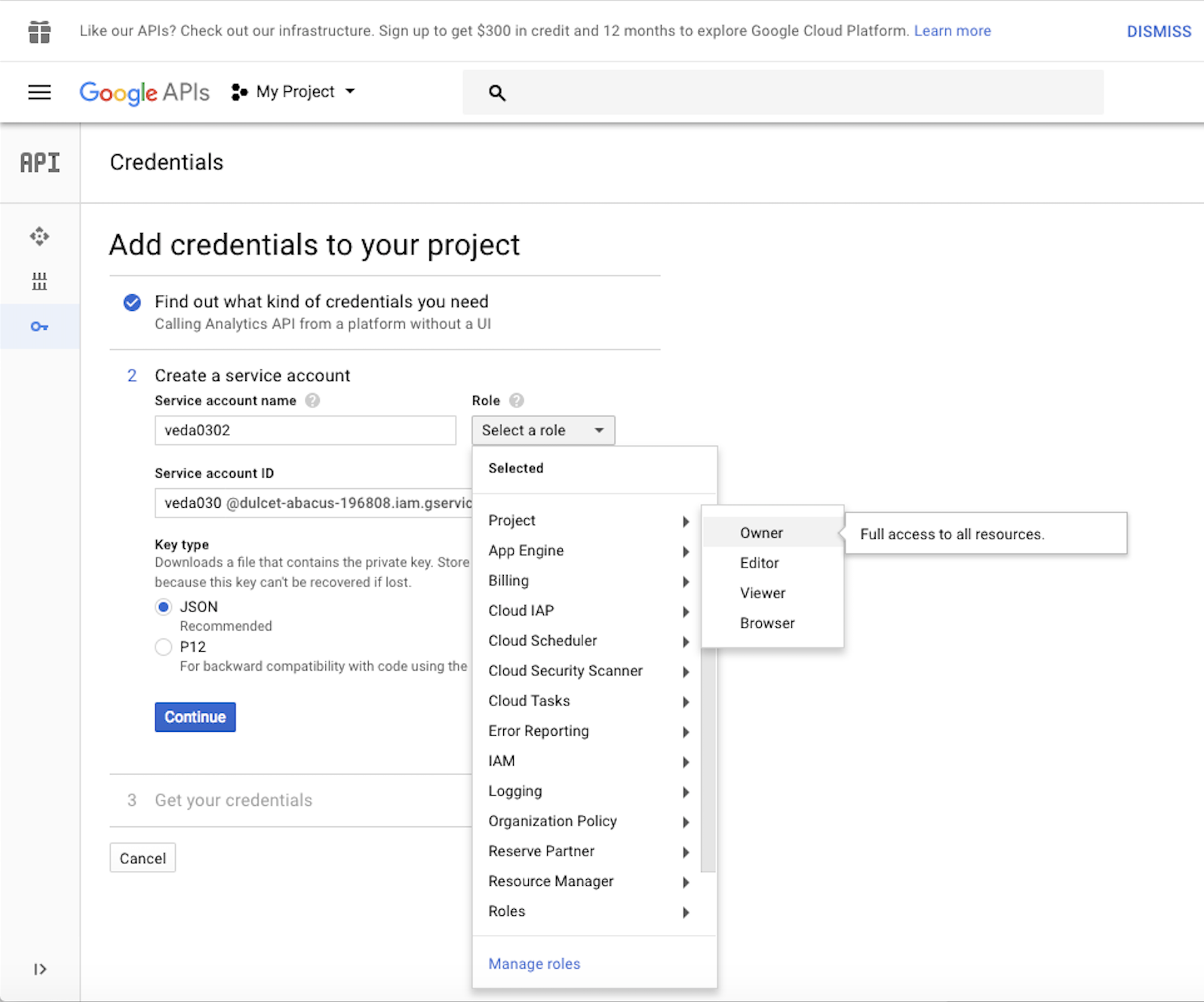
Step 5: The service account and key will get created, and the private key in JSON format will be automatically downloaded to your laptop. Rename this file to client_secrets.json and keep it safely. We will need this file to run the Python application.

Step 6: Close the above dialog box and on the Credentials screen click the Manage Service Accounts in the far right hand corner as shown below.
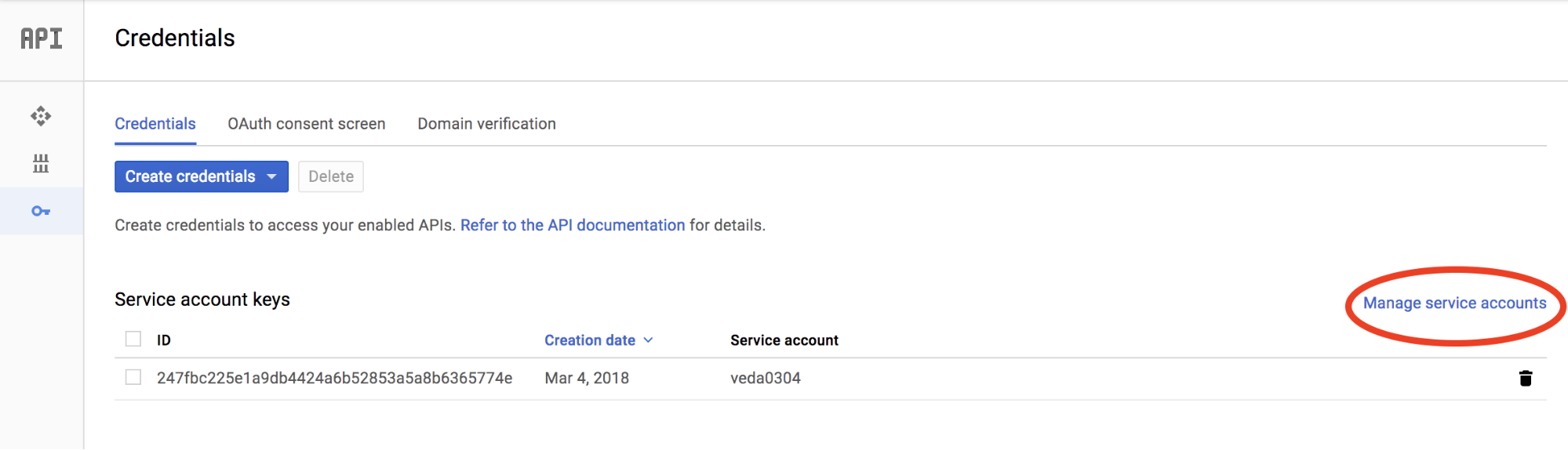
Step 7: This will bring up the details of the service account you just created. Note the Service account ID (@xxx.gserviceaccount.com) for the newly created service account.
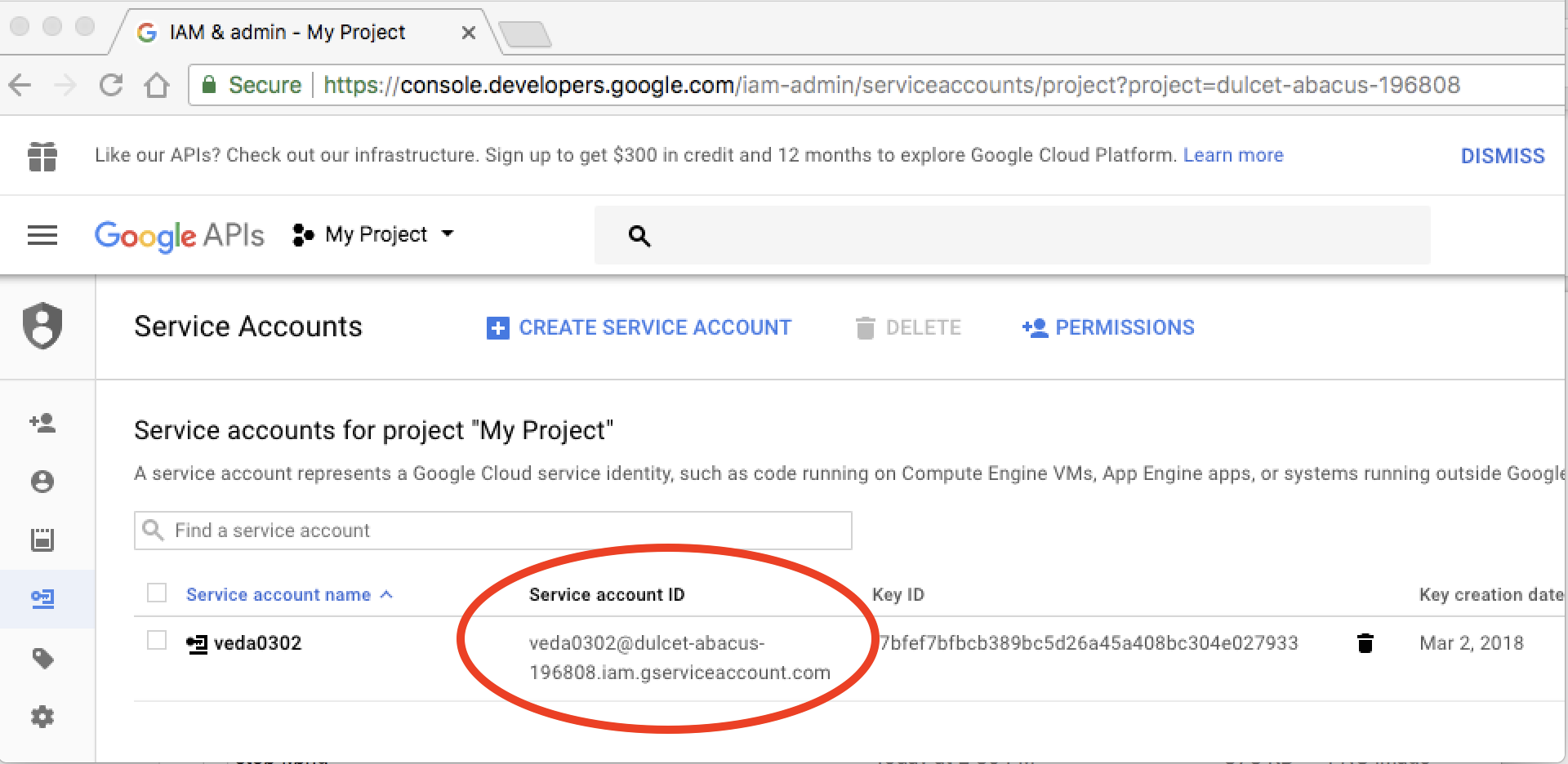
Prerequisite 2: Service Account Connected to Google Analytics Account
Add the Service account ID from the previous step to the Google Analytics account.
- Sign in to Google Analytics.
- Click Admin, and navigate to the desired account/property/view. /li>
- In the ACCOUNT, PROPERTY, or VIEW column (depending upon whether you want to add the user at the account, property, or view level), click User Management. Parent permissions are inherited by default (account > property > view). For example, when you set permissions for a user at the account level, that user then has those same permissions for all the properties and views in that account. As you progress down the hierarchy, you can give more permissions, but not fewer, e.g., if a user has Read & Analyze permission at the account level, you can then also grant Edit permission at the property or view level; but if a user has Edit permission at the account level, you can’t limit permission to just Read & Analyze at the property level.
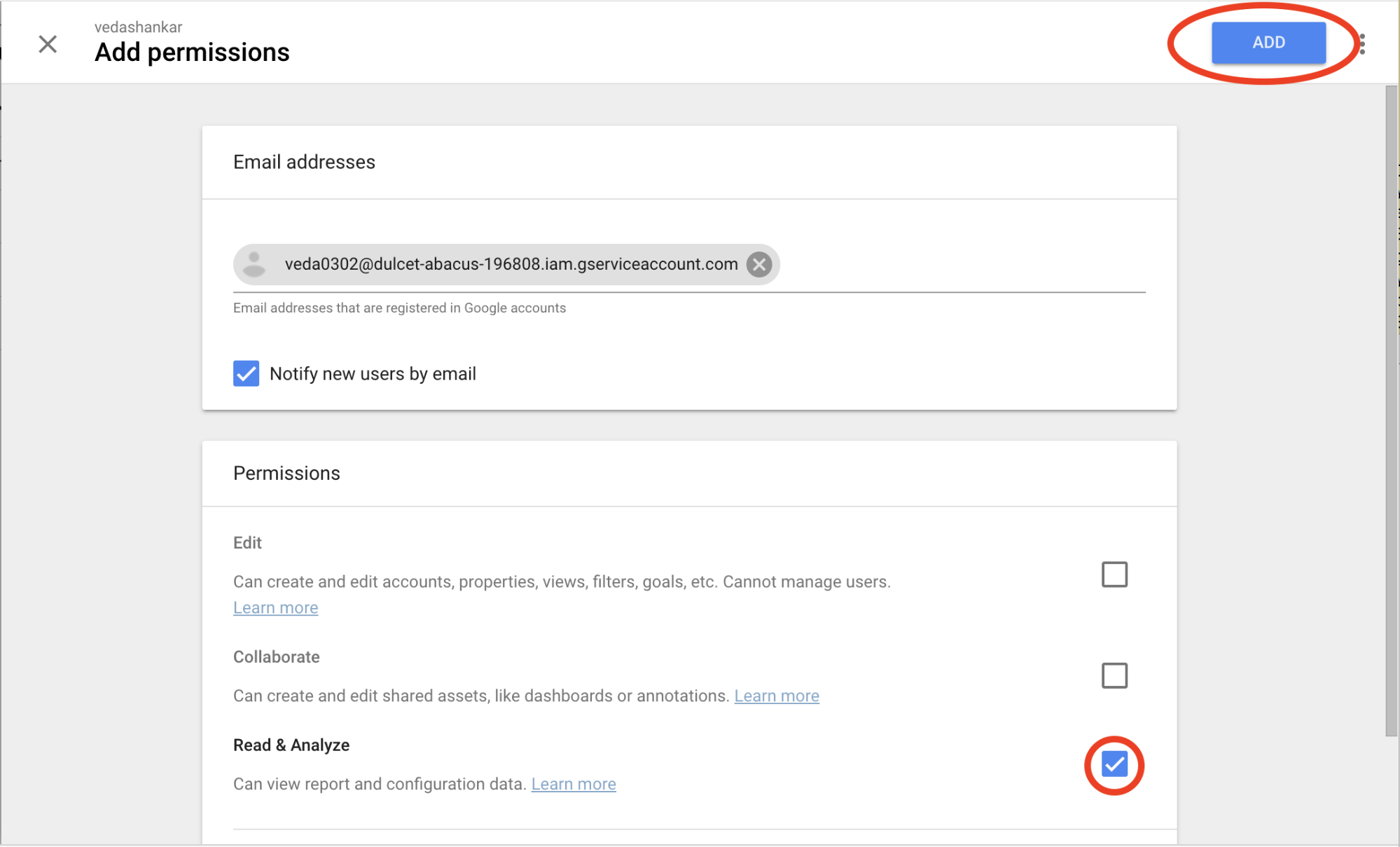
- This will bring up the Account users page, press the + sign at the upper right-hand corner to show the add new users/groups menu. Press the Add new users option.

- Under Add permissions, enter the service account ID for the user's Google Account. Check the box for Read & Analyze.
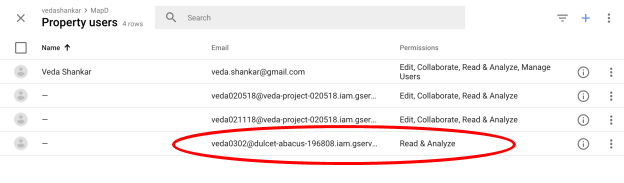
- To confirm that the service account has been added correctly, Click Admin, and navigate to the desired account/property/view. You should see the newly added service account with the required privilege.
Prerequisite 3: Software Packages
The application has been written in Python using APIs from Google Analytics Client Library, MapD APIs, and Pandas data analysis library. The application was tested on a Linux system with Python version 2.7.12 and with the following packages installed:
# pip install --upgrade google-api-python-client
# pip install matplotlib pandas python-gflags
# pip install pymapd
# git clone https://github.com/mapd/google-analytics.git
Make sure to have a passwordless SSH login account on the MapD server in case you want to automatically load the analytics data into the MapD Core database. The alternative is to use the import feature in MapD Immerse user interface.
Workflow of the Google Analytics Importer Application
Here is what the application does:
- Create a service object to Google Analytics using the client_secrets.json file corresponding to the service account that was created in the prerequisite step.
- Traverse the Google Analytics management hierarchy and construct the mapping of website profile views and IDs.
- Prompt the user to select the profile view they would like to collect the data.
$ python mapd_ga_data.py
Item# View ID View Name
1 151405570 MapD Community edition AWS_All Web Site Data
2 151400370 MapD Community edition DL_All Web Site Data
3 160834939 MapD Community edition DL_Non-Dev
4 161106277 MapD Community edition DL_Non-MapD
5 152688532 MapD Enterprise AWS_All Web Site Data
6 108540717 MapD Enterprise installed_All Web Site Data
7 94937405 MapD MIT Twitter Demo_All Web Site Data
8 134050322 MapD Meetup - Enterprise GPU Computing_All W
9 152769575 MapD OS_All Web Site Data
10 168795059 MapD Test Drive_All Web Site Data
11 122232033 MapD Testing_All Web Site Data
12 93521025 MapD Website_Live Site
13 123255922 MapD Website_No Filters
14 160571176 MapD Website_Staging
15 160593821 MapD Website_Staging (testing)
16 94956153 MapD YouTube_All Web Site Data
Enter the item# of the view you would like to ingest into MapD: 2
Item # 2 selected
- Prompt the user to enter the begin and end date range for downloading the data. If you just hit enter without any dates, the application will by default fetch the last 30 days worth of data.
Enter the begin date and end date in the following format: YYYY-MM-DD YYYY-MM-DD
Or hit enter to proceed with the default which is last 30 days data
Date Range: 2017-08-01 2018-02-20
Extract data from 2017-08-01 to 2018-02-20
- Prompt the user to enter the MapD server specific information which includes the name of the server, database login, database password, database name and server ssh login name. The ssh login name will be used to copy the CSV file to a temporary location on the MapD server prior to loading it into the database. If you don’t want to automatically upload the analytics data to MapD and would like to upload it using the Immerse UI, simply hit enter without any information.
The application then starts downloading the records for the selected profile view and saves it to the data directory under the names with the following pattern _.csv. After all the records are saved to the CSV files the function merge_tables() is called to merge all the dimensions from the various tables into a single CSV file .csv. The merge function eliminates records that have empty location (latitude, longitude) fields. The geographic latitude and longitude fields are required for the Pointmap which is used for visualizing the location of data on a world map. The date and time dimensions are combined into a single DATETIME column which is compatible with MapD. If the user entered the MapD credentials while launching the application then the program will invoke the functions in mapd_utils.py file to load the table into MapD. The CSV file is compressed using gzip before calling the MapD load function.
Create table and load data from the CSV file
=======================================================================
Goto MapD Immerse UI @ http://mapd-my-azure-server:9092/
=======================================================================
MapD Immerse Import Wizard
If you want to manually load the table into MapD Core Database then you can use MapD Immerse’s table import feature. Open MapD Immerse -> Click Data Manager -> Click Import Data -> Click the + sign or drag-and-drop the CSV file for upload. Detailed documentation.
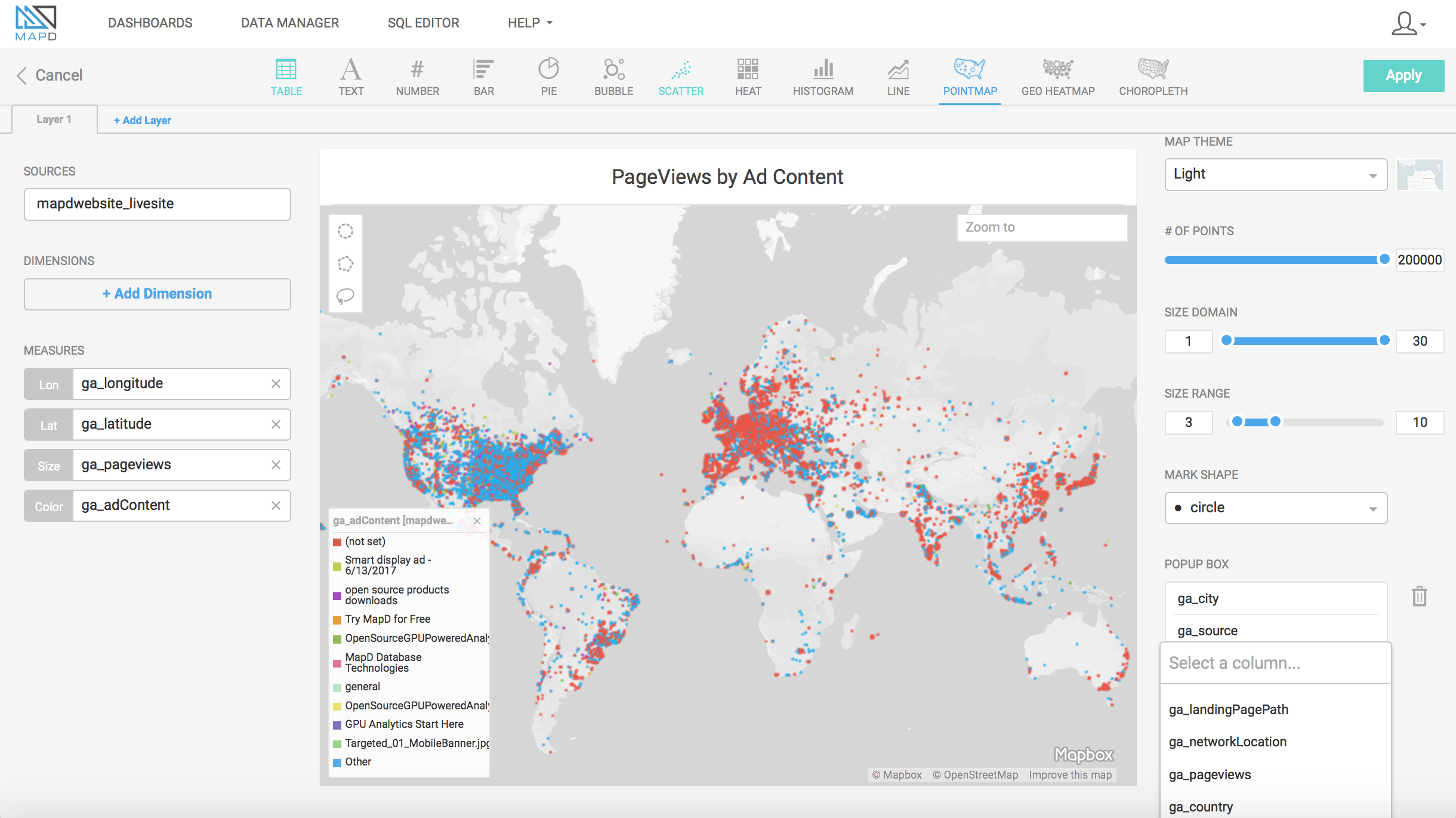
In the next blog we will walk through how to construct a dashboard with various types of charts from the Google Analytics data that we just uploaded to MapD.
Read part 2 of the blog to learn more on exploring Google Analytics data with MapD’s powerful crossfilter feature. We welcome your suggestions for improvement and any questions on this topic at our community feedback forum.



